

Why proprietary data is your most defensible AI citation asset
Original data wins citations, but being the primary source might not. Part 2 in our series about organic authority multiplication.



Publish original numbers. It’s the single most reliable lever for making a page more original, and the most defensible numbers are a byproduct of the business itself… not data you assembled to feed a content calendar.
The old play was paying a PR or research firm for a survey loosely tied to your product, like a car insurance FinTech buying road-trip research to land in Yahoo. That’s outdated. Almost every product now generates data worth publishing, and pulling it has never been easier.
You don’t need a research team. The bar to clear the field is lower than you think.
In this memo:
Original data is the strongest single predictor of page originality
Owning the number doesn’t guarantee the citation. Structure and trusted-source presence decide who gets it.
Built your content for extraction for better chances of earning the citation
Coming up next week: We’re finalizing a new analysis on using first-party data to establish brand authority and visibility—keep an eye out for it. It drives the findings of this memo even further.

Meet the AI visibility leaders in retail, plus new tactics

AI search is reshaping customer journeys and how shoppers discover and choose products. But many retail marketers don’t yet have a clear benchmark of AI visibility, who’s winning and why.
Semrush’s AI Visibility Index changes that. Our new study is built on a US prompt database of 126 million prompts, mapping exactly which retailers are dominating AI recommendations across ChatGPT, Google AI Mode, Gemini, and AI Overviews. As well as where the opportunities lie.

First-party data: The strongest correlation of originality
On-Page.ai’s recent information gain study scored 150 top-3 Google pages across 50 keywords and 10 verticals on how much each adds beyond the rest of its ranking cohort, grading the contribution from 0 to 100 by meaning rather than wording.
The median page scored 52, and original data correlated with that score more than any other page-level trait, including length.
Pages with at most 1 unique figure averaged an information gain score of 40.2, while pages with 15 or more averaged 62.1, and the score climbed steadily at every step in between
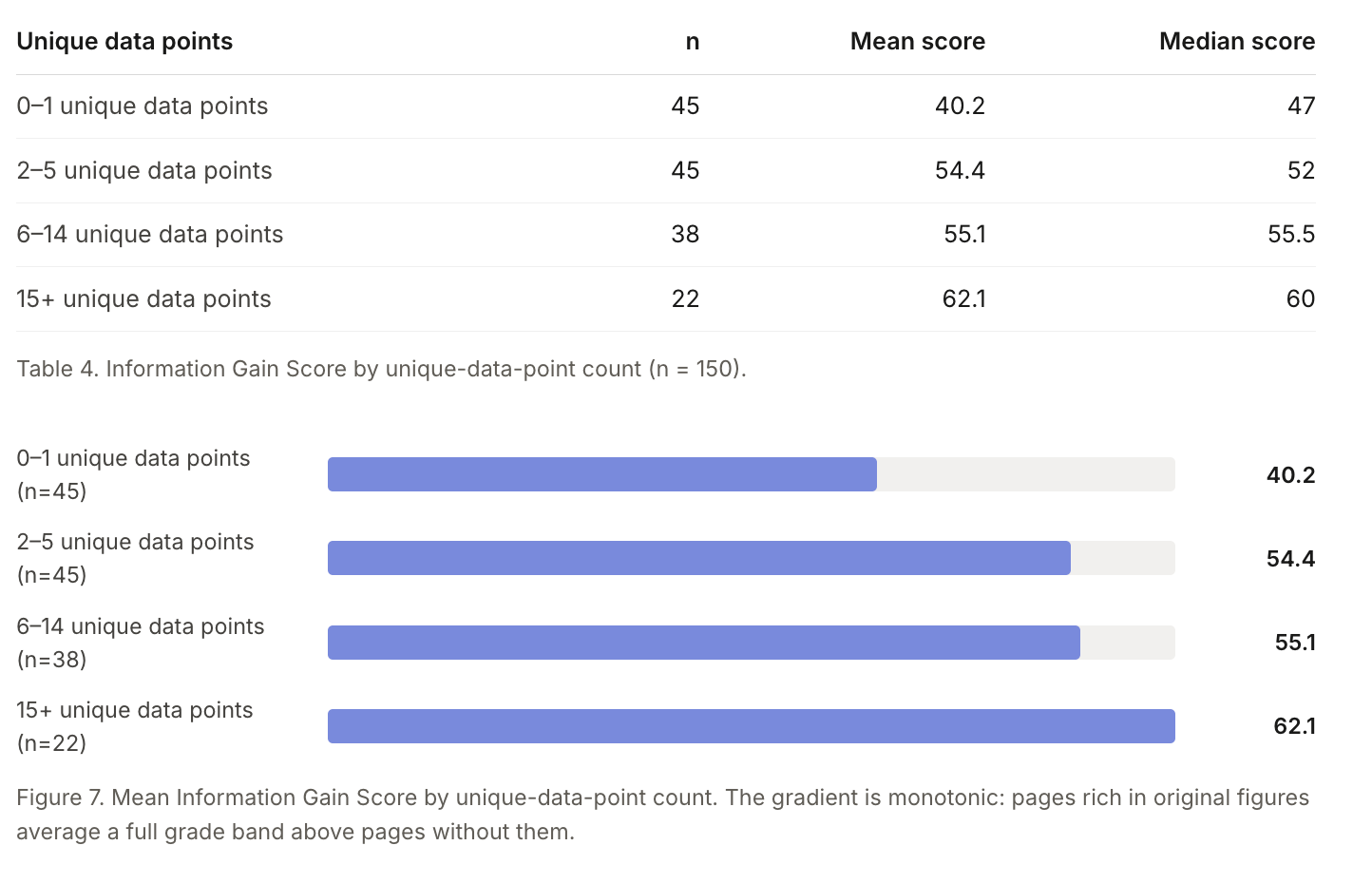
Good news, the bar to beat is low. The study found that it might not take much original evidence to outclass top-visible pages in classic Google search: top organic results typically have only 4 unique data points on average. Publish a page that includes more than 4 real original claims, figures, or answers, and that’s one more lever to pull for increasingly competitive organic visibility.
This analysis also found that in almost every search, there are plenty of adjacent unanswered questions that are being left on the table. On-Page ran their analysis with synthetic reader questions, a sample of plausible questions generated for the study, that were a closely related set to the search topic of each query, and results showed an open door for new pages to answer them and stand out. (Remind you of anything? Query fan-out, perhaps?)
We had a similar finding in an analysis of ChatGPT citations:
“A single evergreen page covering 10+ query intents is worth more in AI citation reach than 10 single-intent pages. The ROI of comprehensive content is front-loaded: one well-built page compounds citation reach over time. The long tail exists, but the top 5% of pages capture a disproportionate share of ongoing citation activity.” - The science of how AI picks its sources
In fact, your brand’s high-intent prompts should be monitored across a journey for this purpose. Turn them into journeys that follow the buyer across the 5 stages from Reasoning Lift: Problem, Exploration, Comparison, Validation, Selection. (Read more about more accurate AI prompt tracking here.) Answer those questions on the page with the knowledge and expertise that only your brand can to stay competitive against this finding in the analysis.
The main takeaway from the findings: Most pages are middling on originality, genuinely original pages are a minority, and scoring high enough to stand out is achievable… without being an extraordinary feat or lift.
The gap in the findings? This study focuses on classic search visibility and rankings (the SEO concept of information gain was birthed out of a Google patent language, after all). It doesn’t take AI citations or mentions into consideration, and there’s no mention of including AI Mode or AI Overviews in the analysis.
Caveat: Being the primary source alone may not win the citation
This is the part most proprietary data-publishing advice skips. Everyone says publish original research. Few test whether AI rewards the brand that originated the number or the page that presents it most readably.
More data analysis is coming next week, but what we do know from analyses we’ve completed at Growth Memo this last year:
The entity types that predict ChatGPT citations the most are DATE and NUMBER (from The science of what AI actually rewards). High-cited pages are dense with specific entities: a particular methodology, a precise statistic, a named comparison. Even if your proprietary findings are picked up by another source that is cited instead, i those external third-party authority signals are likely to build.
Entity-richness and balanced sentiment matter (from The science of how AI pays attention). Generic advice is risky and vague, but specific entities are grounded and verifiable. Proprietary data produces, verifies, or validates and creates entity-rich content. (Think: why a feature works to save % of dollars, how many hours saved by clients vs. competitors they worked with before, etc.). Add balanced sentiment into the analysis and explanation of your data, and you’ve got yourself a 2-for-1 tactic.
If the hypothesis that first-party data is crucial in the era of AI search holds, publishing content based on proprietary data is necessary… but it is not sufficient. LLM extraction structure (along with the sites that AI search engines trust for the topic) decides who gets the citation, even when your brand owns the data.
Unfortunately, an aggregator who repackages your benchmark into a cleaner answer-ready page can collect the citation your research earned. (Truth sucks.)
Who wins: Brands sitting on proprietary product, usage, or pricing data who also structure it for extraction and don’t ignore other organic brand authority building plays. (Learn more in How to build an AI SEO strategy that outlasts tactics.)
Who loses: Brands producing opinion content any tool can replicate, ignore other crucial ways of building off-site authority, along with primary sources who bury their own numbers in narrative instead of surfacing them.
Whether some verticals reward data content more than others, we do not know yet. The science series found citation signals vary sharply by vertical, so a uniform payoff would be the surprise, but we will not assert a pattern without data.
Head’s up: Reading this data is one thing. Running the training session that changes how your writers write is another. Premium subscribers get the How AI Pays Attention training deck plus the AEO writing checklist. The slides and the exercises are already built.
How to structure data for extraction
Owning the data gets you into the fight for visibility. But how you structure your content could be what wins it.
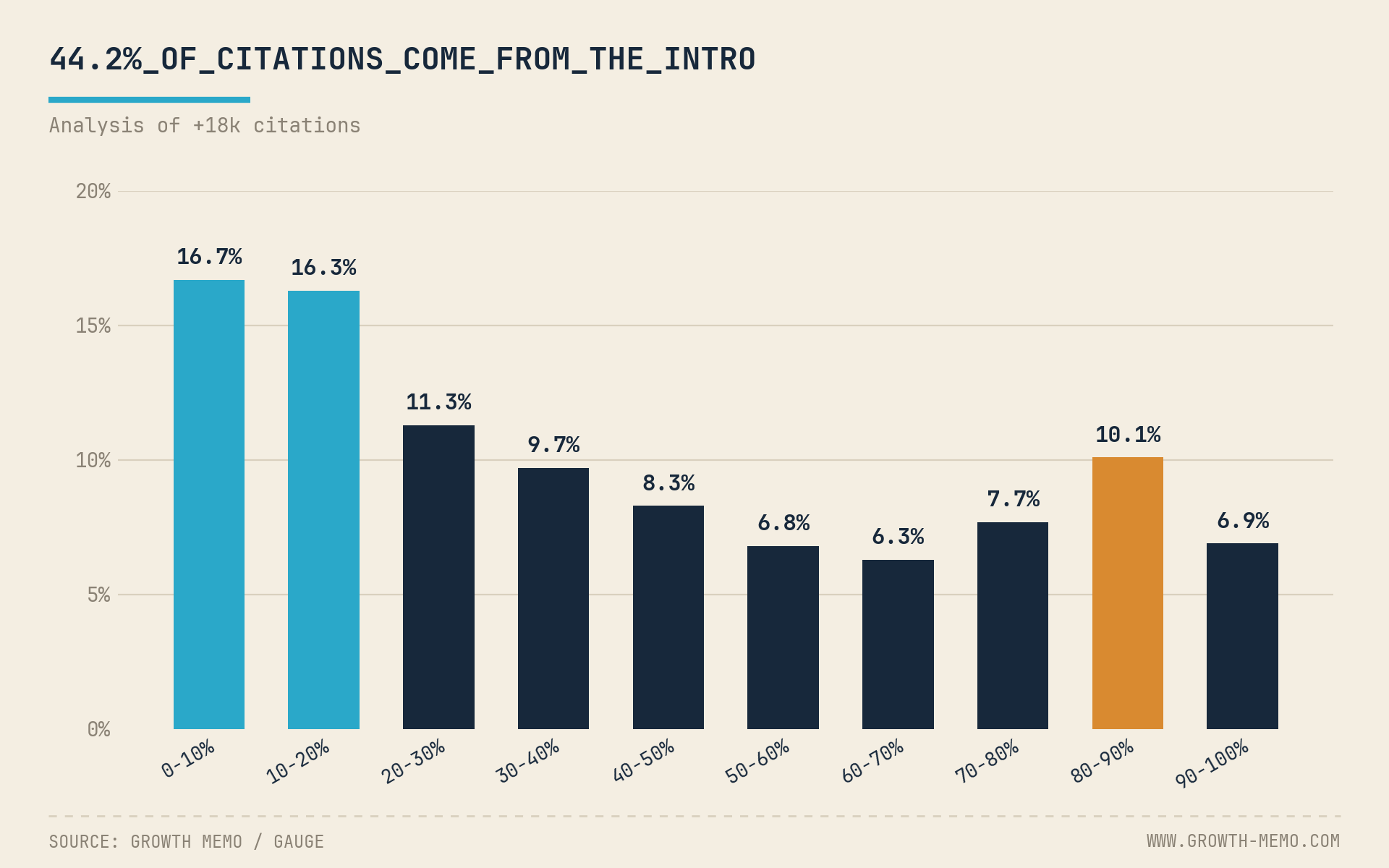
We analyzed 18,012 verified ChatGPT citations and found a ski-ramp distribution: 44.2% of all citations come from the first 30% of a page. The middle 30-70% earns 31.1%, and content buried deep in a long post is roughly 2.5x less likely to be cited.
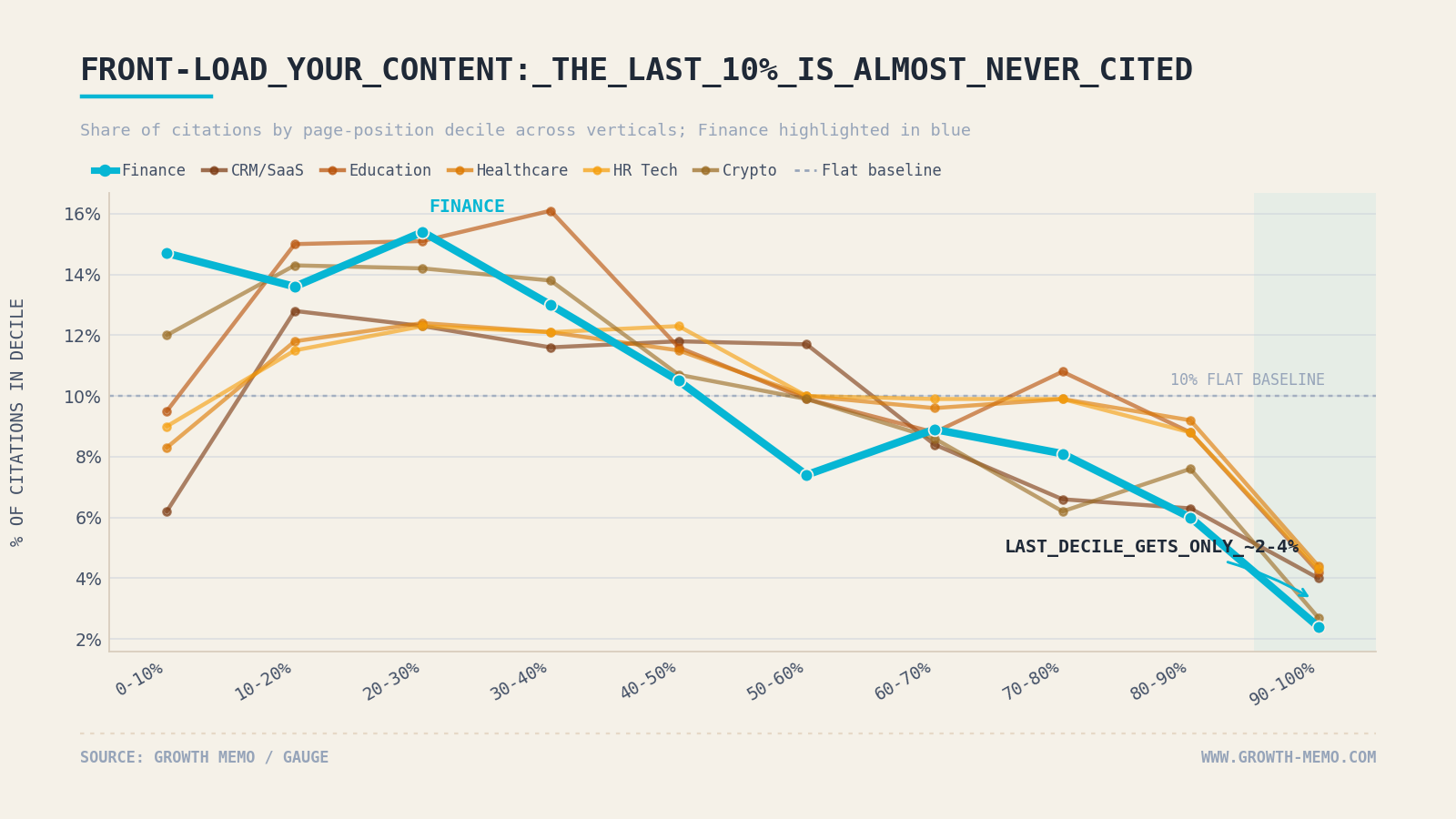
The follow-up analysis across 7 verticals sharpened the target: The 10-20% band of a page is where AI reads hardest in every vertical, while the first 10% is typically navigation and intro filler that AI skips. The bottom 10% of any page earns 2.4-4.4% of citations regardless of vertical.
Applied to a data study, the structure of your content writes itself:
1/ Lead with the headline statistic. Your strongest number goes in the first 30% of the page, ideally right after the title block where the 10-20% band begins. Number → comparison → implication, in the first screen.
2/ Define the metric immediately. One sentence on what the number measures and the population it covers. An undefined statistic is harder to lift with confidence.
3/ Box the methodology. Sample size, time window, collection method, in a short labeled block. Attribution confidence is part of what makes a number citable.
4/ Front-load every secondary finding. Findings ranked by strength, strongest first. The 20-paragraph narrative buildup is a human-retention pattern that costs you machine citations.
5/ Skip the suspense close. AI reads like a busy editor, not a patient student. The payoff-at-the-end structure that worked for ultimate guides actively works against extraction.
What sites are trusted in your brand’s topics? When an aggregator collects the citation your research earned, it’s because they’re already in AI’s trusted-source set for the topic and you’re not. The Citation Source Mapper maps that set into a ranked, pitchable target list. It’s in the premium library.
Premium: 6 first-party data plays by category
You don’t need a research budget to publish original data. Every business produces data it never publishes.
Below are 6 plays, each tied to a type of data your business already produces, so you can match the play to the byproduct you already own.
