

Make your prompt tracking more accurate this week
AI Visibility is measurable. The mistake is running it like a rank tracker.


By now, you understand that LLMs are probabilistic systems and that AI answers are highly variable. That fact has convinced a lot of people that prompt tracking is extra noise. But discounting prompt tracking as nonsense is the wrong conclusion.
Even though prompt tracking is much less deterministic than keyword tracking, we can significantly increase the accuracy of tracking AI mentions and citations. Repeated runs, fixed sampling rules, and confidence intervals turn variance from a reason to quit into a number you can defend.
By the end of this Memo, you’ll know how to build that system.
This memo assumes that you’re already:
1/ Operating under the philosophy of persona-based prompt design, argued for in Synthetic Personas for Better Prompt Tracking.
2/ Bought into doing AI SEO / AEO and need a measurement system that actually tracks your progress vs. noise. Check out How Much Can We Influence AI Responses to learn more.


AI Mode is expanding. The Search box just got its biggest AI upgrade in decades. Search agents now crawl the web and answer for users in the background, before anyone reaches your page. If you’re still grading yourself on rankings and traffic, you’re scoring a game that no longer exists.
Chris Long, co-founder of Nectiv, breaks down what changed, what it means for B2B visibility, and how to build the workflows that get you cited in AI search.
You’ll walk away knowing:
Why the SGE to AI Overviews to AI Mode shift is bigger than it looks
The I/O 2026 updates that belong on your roadmap now
How to measure visibility past rankings: citations, prompt coverage, mentions
What makes content surface in fan-out and decision-stage queries
The workflows to audit, refresh, and publish content built for AI search
Date: June 17 · 3pm ET · Zoom · Recording sent after
Spots are limited. Claim yours before Search moves again.

The prompt-tracking backlash is only half-right
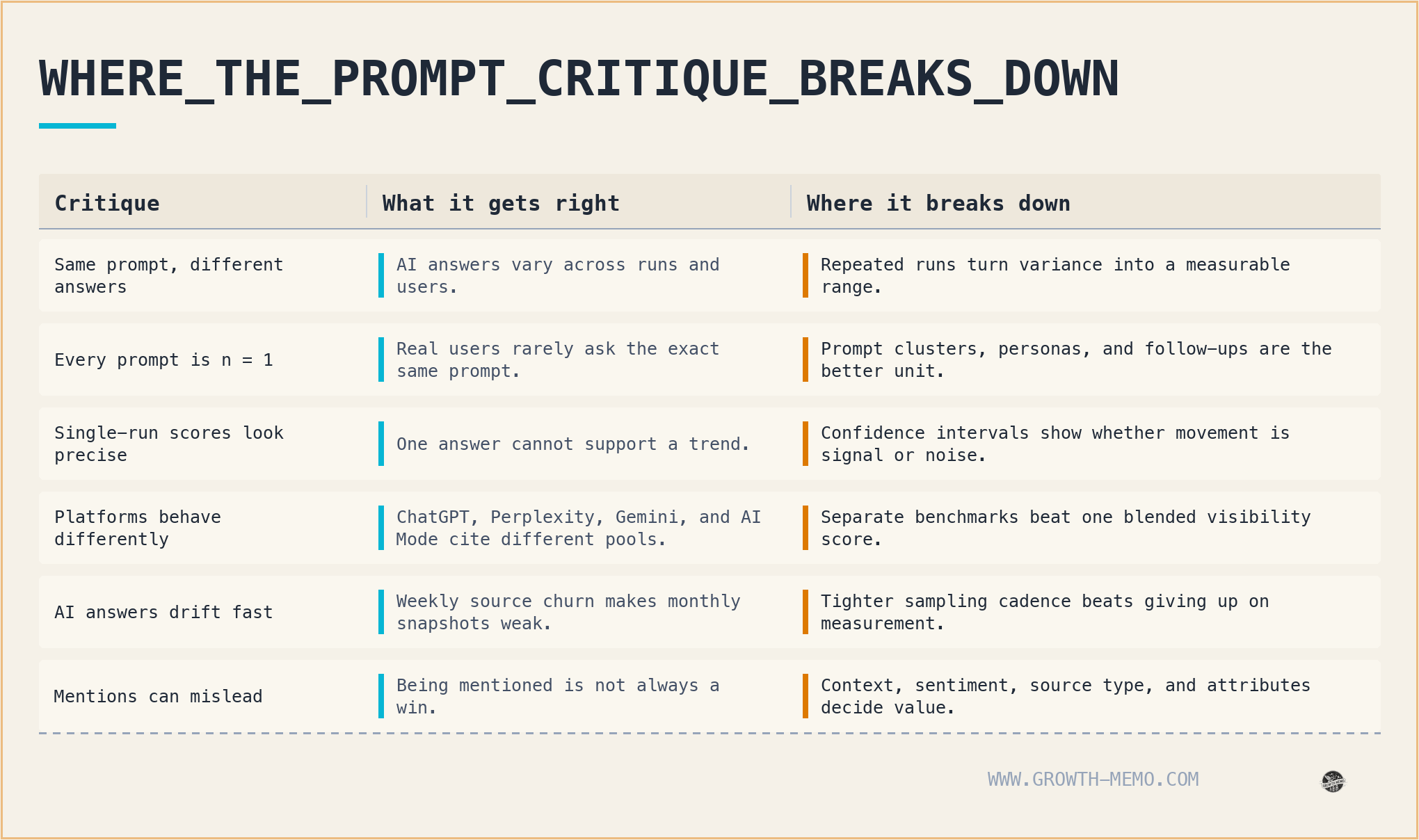
Prompt tracking critics are not wrong. 5 people running the same prompt get 5 different answers. Within-LLM variance from sampling alone hits 10-34% on identical prompts.
Reporting a point estimate from one run is astrology. Together with AirOps, I looked at 815,000 prompt-page pairs and found that after running the same prompt 3x in ChatGPT, only 2.2% of citations remain.
Every prompt is n = 1. Given that the average prompt is 5x longer than classic search keywords, the chance that 2 people around the world use the same exact prompt is close to 0. We currently don’t have any insight into what users prompt, and we might never get that data (although both Bing and Google are keeping us satiated, for now, by offering some AI-visibility data).
But “probabilistic = unmeasurable” is lazy thinking. Weather is probabilistic. Credit Scores are probabilistic. We still forecast and track them.
Keyword tracking was never as clean as we’d like to remember
Classic keyword tracking was more deterministic, but not as much as you think:
For local searches, results were personalized by location and device.
Google re-scores results daily, so every rank tracker reports a position range, not a fixed number.
The industry standardized the sampling, fixed location, clean profile, daily crawl, etc., until the noise disappeared. Prompt tracking needs the same move, applied to a harder problem. An added challenge: Keyword tracking was focused on Google, but now we have tons of engines. As the market consolidates, tracking simplifies.
I’d argue there’s no escaping this either as Google transitions from classic search to AI search. More searches than ever show AI Overviews (AIOs), all while AIOs and AI Mode increasingly merge.
At I/O 2026, Search head Liz Reid said users increasingly ask “longer, more natural-language questions,” and Sundar Pichai described Search as “less about individual queries” and “more like an ongoing conversation” (blog.google[KI1] [KI2] /innovation-and-ai/sundar-pichai-io-2026, May 2026).
Where common prompt tracking breaks
Over the last 2 years, prompt tracking tools multiplied while the methodology behind them stalled. Where’s the innovation?
The common prompt-tracking approach looks something like this:
Define 25–50 prompts (brand/category/problem split)
Run each prompt once per platform
Track daily
Score for citation, mention, sentiment, position
Here are the problems I see with that approach:
Variance: Only 2.3% of citations remain after 3 prompt runs [The Consensus Gap]. One run is a coin flip with the answer hidden.
Reasoning: High vs. low reasoning opens an 18 percentage point citation-rate gap and changes how the model searches, with high reasoning firing 4.6x more fan-out queries [Reasoning Lift]. An aggregate score blends 2 different engines into one misleading number.
Personalization: Most prompt-tracking is not persona-specific, so it reports generic answers that no one sees.
Monthly cadence: SISTRIX tracked 82,619 prompts over 17 weeks and found Google AI Mode replaces 56% of its cited sources every week, while ChatGPT replaces 74%. At that drift, monthly tracking is like checking your bank account once a quarter.
Cross-platform aggregation: Blending your ChatGPT + Perplexity + Gemini visibility into one “AI visibility score” is like averaging your Google rank with your Bing rank.
Conversations: A single Turn 1 query tells you whether you get mentioned. It says nothing about whether you survive Turn 2 onward, when the user asks about alternatives, pricing, integrations, or risk. AI is a conversational interface, so the journey is the unit of measurement, and a one-shot prompt misses most of it.
Context: Pure mention counting with no context treats every appearance as a win. Get named first for “what are the worst CRMs to avoid?” and a mention tracker still records a victory.
So, while we can’t remove AI answer variance, we can run prompts multiple times and measure what parts, brand mentions, and citations of the AI answer remain.
Mirroring follow-up prompts is hard because we don’t know exactly what people will ask, but we can use AI to estimate likely follow-ups, enrich them with real conversation transcripts, and track the follow-ups LLMs suggest inside their own answers. We can also record the attributes a brand gets mentioned with, not only whether it shows up.
What good prompt tracking looks like in practice
Worked example: B2B SaaS, CRM category.
Prompt set: 40 seed prompts, weighted toward problem prompts where purchase intent lives (12 brand, 12 category, 16 problem).
Platforms: ChatGPT, Perplexity, Gemini, Google AI Overviews. Tracked separately.
Run config: 5 reps per prompt per platform, every week.
Personas: the 28 category and problem prompts are customized for 3 key personas (CFO, IT, marketing).
Metrics: mention rate (± CI), citation rate (± CI), average position when mentioned (1-5), sentiment, and the attributes attached to each mention.
Level it up by adding the journey layer. A flat list of 40 prompts only measures Turn 1. To measure conversations, build the high-intent prompts into journeys that follow the buyer across the 5 stages from Reasoning Lift: Problem, Exploration, Comparison, Validation, Selection.
Each seed prompt for Turn 1 becomes the “seed prompt,” and each stage adds a natural follow-up prompt on subsequent turns.
For a buyer evaluating CRMs, one journey runs:
Problem: “How do I know if my sales team needs a CRM?”
Exploration: “What types of CRM software exist for B2B SaaS?”
Comparison: “HubSpot vs. Salesforce vs. Pipedrive for a 50-person sales team”
Validation: “Is HubSpot worth the price for mid-market B2B?”
Selection: “How do I get started with HubSpot Sales Hub?”
Run the full sequence as 1 conversation rather than 5 isolated prompts, and score every turn. The payoff is persistence: in Reasoning Lift, a brand cited at the Problem stage carried all the way to Selection in 4 journeys under high reasoning and in zero under minimal. Persistence is the metric a one-shot tracker can never see.
Scope it so the run volume stays sane. Track all 40 seed prompts at Turn 1 for breadth, and build the 16 problem prompts into full 5-stage journeys for depth.
Insight example: HubSpot is mentioned in 78% ± 6pp of fiproblem prompts on ChatGPT vs. 34% ± 9pp on Perplexity. Perplexity pulls from comparison posts (G2, Capterra); ChatGPT pulls from HubSpot’s own blog plus integration and compliance docs.
Action: invest in integration guides and API docs to win ChatGPT. Invest in G2 review velocity and comparison content to win Perplexity.
The next generation of tracking looks like polling
Prompt tracking won’t become keyword tracking. AI answers are too variable, too personalized, and too dependent on source selection. But that doesn’t make them unmeasurable.
The next iteration of prompt tracking will look less like rank tracking and more like polling: repeated runs, clear sampling rules, confidence intervals, segmented panels, and raw-answer audits.
Until existing tools get there, you can build a simple version yourself.
Premium: How to upgrade your prompt tracking
You now know why single-run, monthly, blended prompt tracking misreports reality. Here is the build to fix it.
