

Reasoning lift: What happens to AI visibility when AI thinks harder
High reasoning fires 4.6x more searches cites a nearly different web.

This Memo was sent to 26,659 subscribers. Welcome to +100 new readers! Upgrade to Premium for the full archive, research, frameworks, and templates
AI offers a conversational experience. We use LLMs through chatbots. But no one has yet looked at how citations and mentions evolve in a conversation.
I analyzed data from the Semrush AI Visibility Toolkit to review 20 buyer journeys across 4 different verticals to compare high vs. low reasoning for ChatGPT5.2.
In this analysis:
Why high reasoning cites a nearly different web (only 25.6% domain overlap with minimal) and which source types gain or lose ground
Why TOFU content has a payoff again: Grands cited at the Problem stage are more likely to persist all the way to Selection under high reasoning, and never under minimal
How to split your prompt tracking by reasoning mode so your AI visibility reporting reflects 2 different systems, not an averaged one
Premium subscribers also get bonus data from the full analysis and the Buyer Journey Prompt Map: a fillable worksheet that turns these findings into a stage-by-stage audit of where your brand persists across an AI buyer journey, and where it goes missing.

Discover how people are really searching, discovering, and engaging online

AI continues to reshape how users discover, engage, and click across search environments. But most teams are still making decisions without a clear picture of what’s actually shifting.
The Datos State of Search Q1 2026 report, created in collaboration with Rand Fishkin, maps real search behavior across millions of users in the US, EU, and UK. AI adoption, regional contrasts, e-commerce discovery, and intent signals are all explored in detail using real clickstream data.

Methodology
Data comes from the Semrush AI Visibility Toolkit, which captures the prompts, citations, and fan-out queries ChatGPT generates per response.
We ran 100 prompts twice through GPT-5.2, once with minimal reasoning and once with high reasoning, for 200 total responses.
Prompts span 20 buyer journeys across 4 categories (B2B SaaS, Finance, Consumer Tech, Health/Lifestyle), with 5 stages per journey: Problem, Exploration, Comparison, Validation, Selection.
Citation rate is the share of prompts where the response cited at least one external source.
Avg citation counts sources per cited response.
Fan-out queries are the sub-queries the model fires internally to research the prompt before answering, surfaced via the Semrush API.
GPT 5.2’s high reasoning cites and searches more
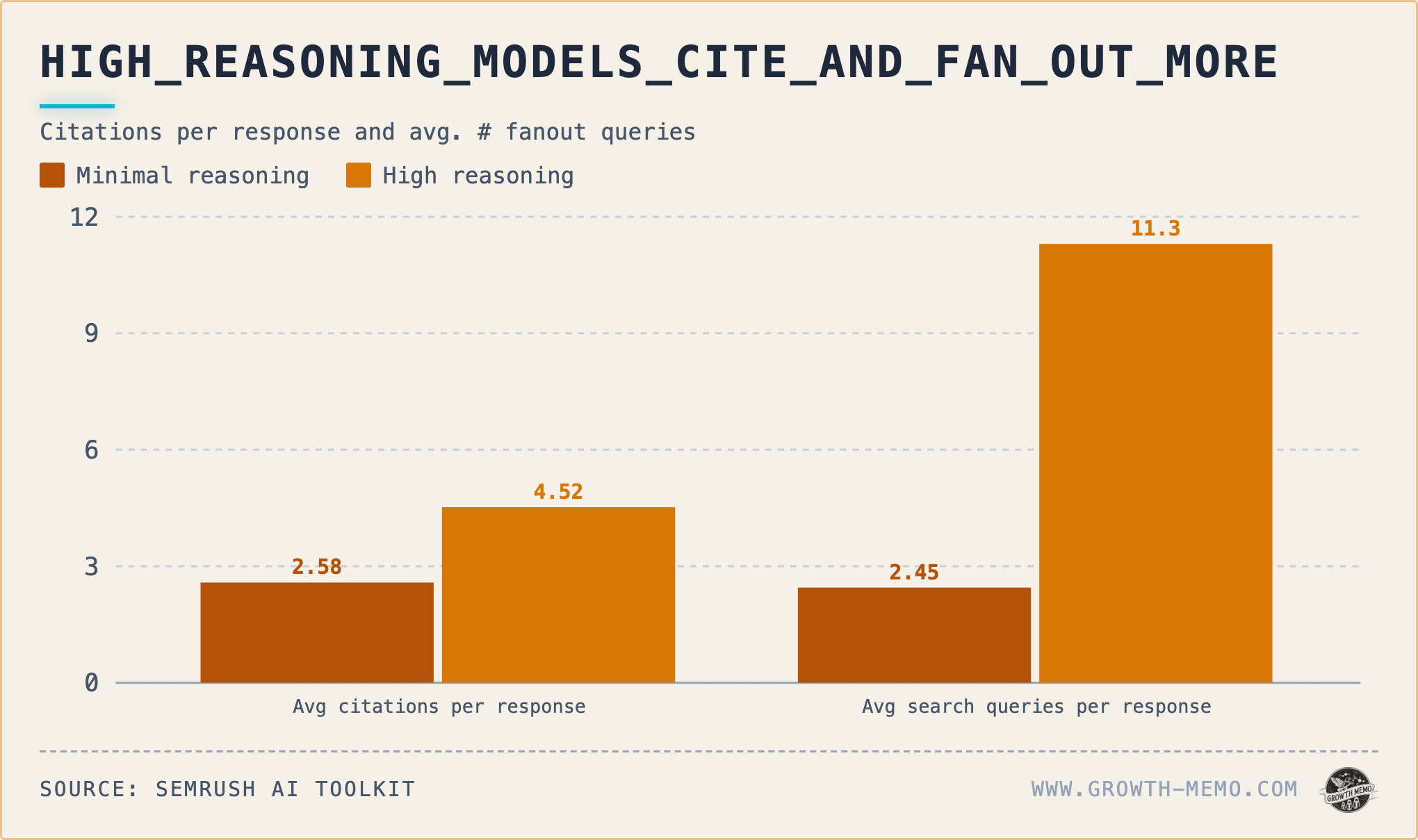
Turn high reasoning on, and the citation rate jumps from 50% to 68% (+18 percentage points), the average sources per response nearly doubles (2.6 to 4.5), and fan-out queries go up 4.6x. High reasoning also pulls from 173 unique domains across the test set vs. 127 for minimal; 99 of those domains never appear under minimal reasoning.
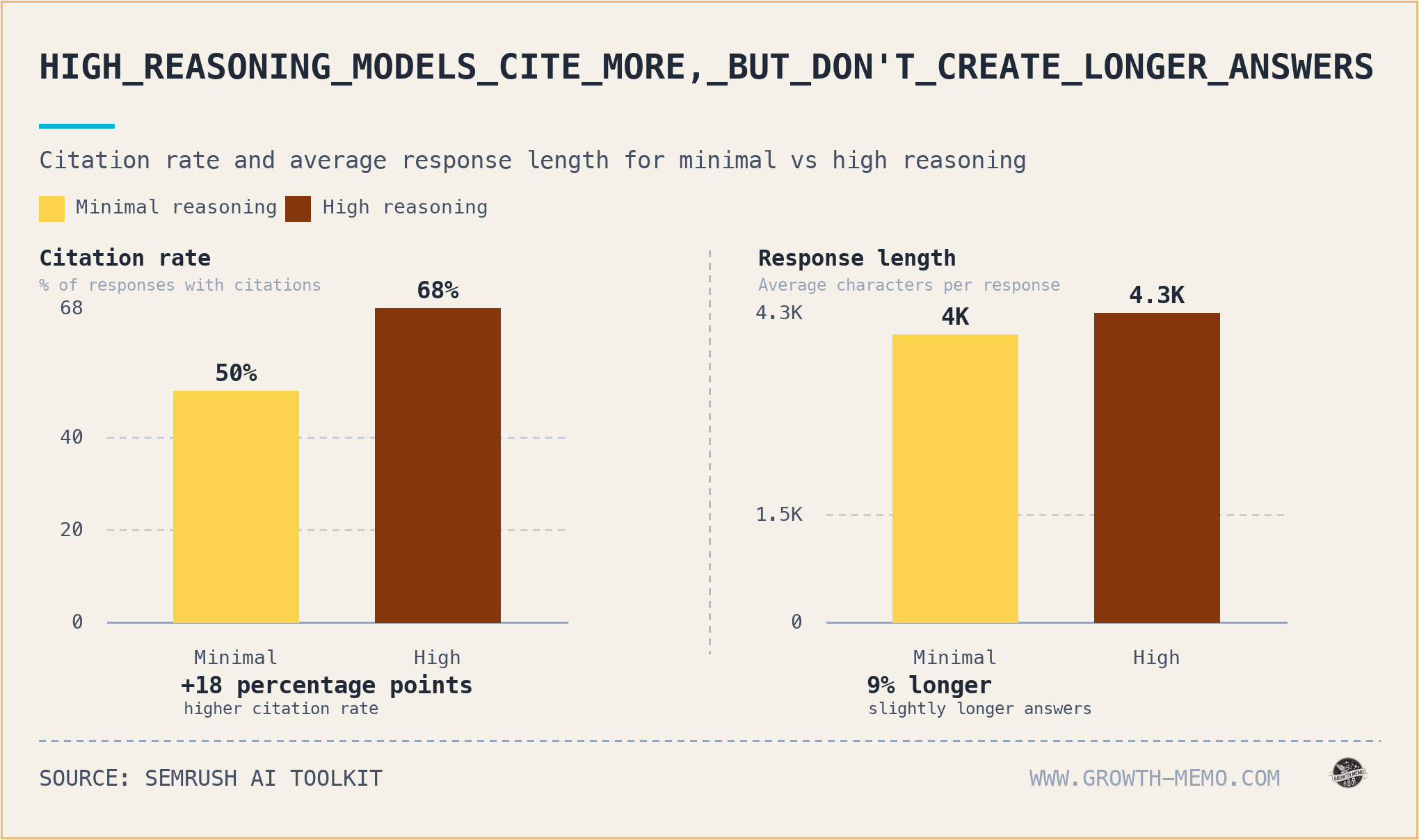
This is grounding at its finest. When the model thinks harder, it relies more on web search. Reasoning plays a major role in brand visibility, though we don’t know how many users activate reasoning vs not.
Query intent is a cleaner proxy than user demographics. Free-tier users have reasoning access too, just rate-limited, and ChatGPT auto-routes hard prompts to Thinking mode without the user clicking anything. So the question isn’t who can afford reasoning. It’s which prompts trigger reasoning automatically.
Multi-criteria comparisons, evaluation frameworks, regulatory and compliance questions, and complex shopping builds are the prompts most likely to fire reasoning regardless of plan. Map your audience by query type, not by paywall status.
High reasoning fires more fan-out queries deeper in the funnel
Users move through problem-solving and purchase decisions in stages, often within the same conversation. The gap between minimal and high reasoning isn’t constant. It scales with where the user sits in the journey.
What the 5 stages look like in practice. Take a buyer evaluating CRM software:
Problem: “How do I know if my sales team needs a CRM?”
Exploration: “What types of CRM software exist for B2B SaaS?”
Comparison: “HubSpot vs. Salesforce vs. Pipedrive for a 50-person sales team”
Validation: “Is HubSpot worth the price for mid-market B2B?”
Selection: “How do I get started with HubSpot Sales Hub?”
The 3 patterns hold across all 20 journeys:
Citation rate climbs through the funnel under both modes, but high reasoning closes the early-stage gap most aggressively: +35pp at Problem, only +5pp at Validation. The model treats early-funnel questions as research tasks when high reasoning is on, whereas it answers-from-memory when it’s off.
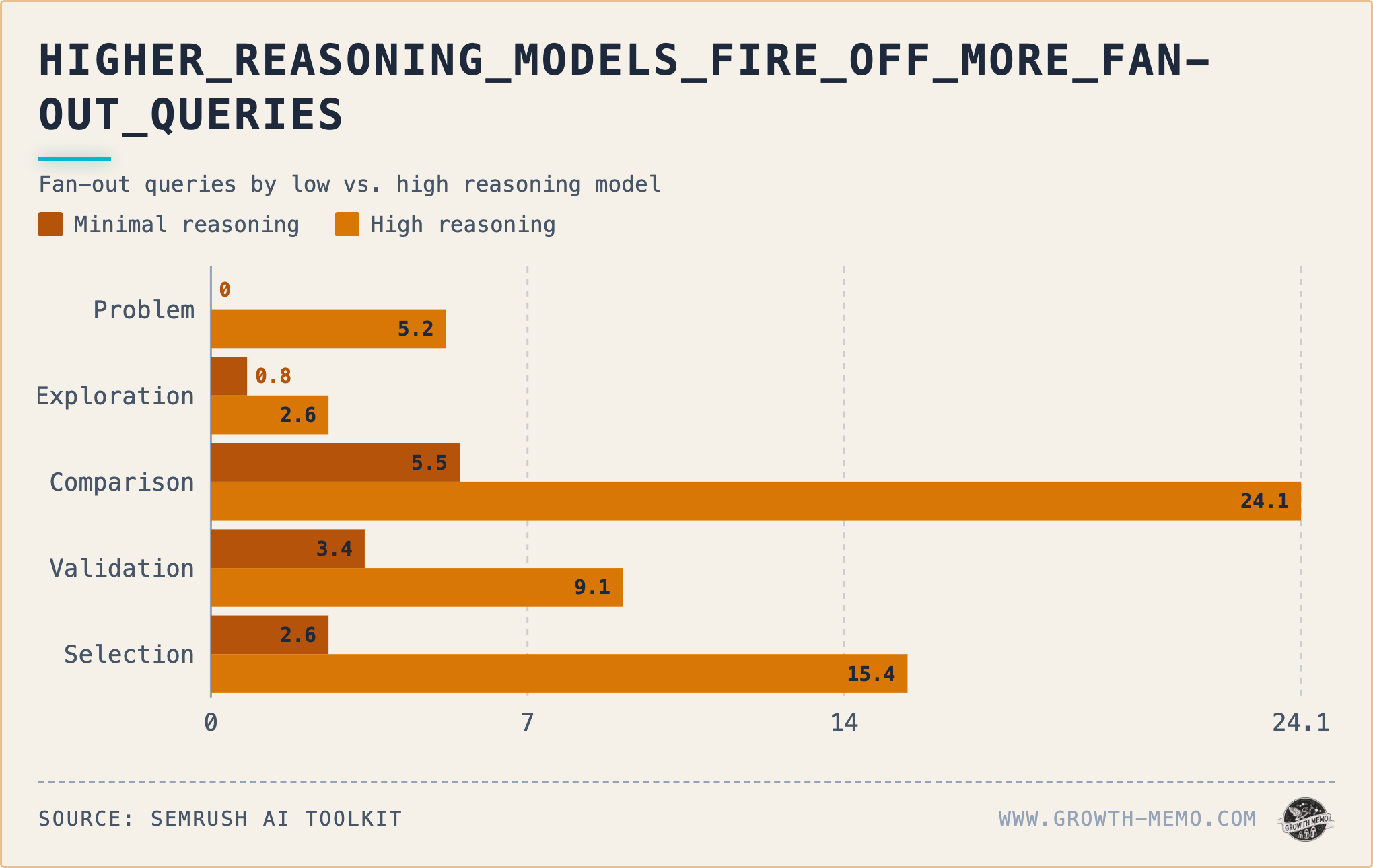
Fan-out queries peak at Comparison. High reasoning fires 24 sub-queries per response there vs. 5.5 for minimal. Selection runs 15.4 vs. 2.6.
Average citations per response peaks at Comparison (9.8 high, 5.8 minimal) and narrows at Selection (4.7 high, 2.6 minimal). The model resembles an hourglass across funnel stages.
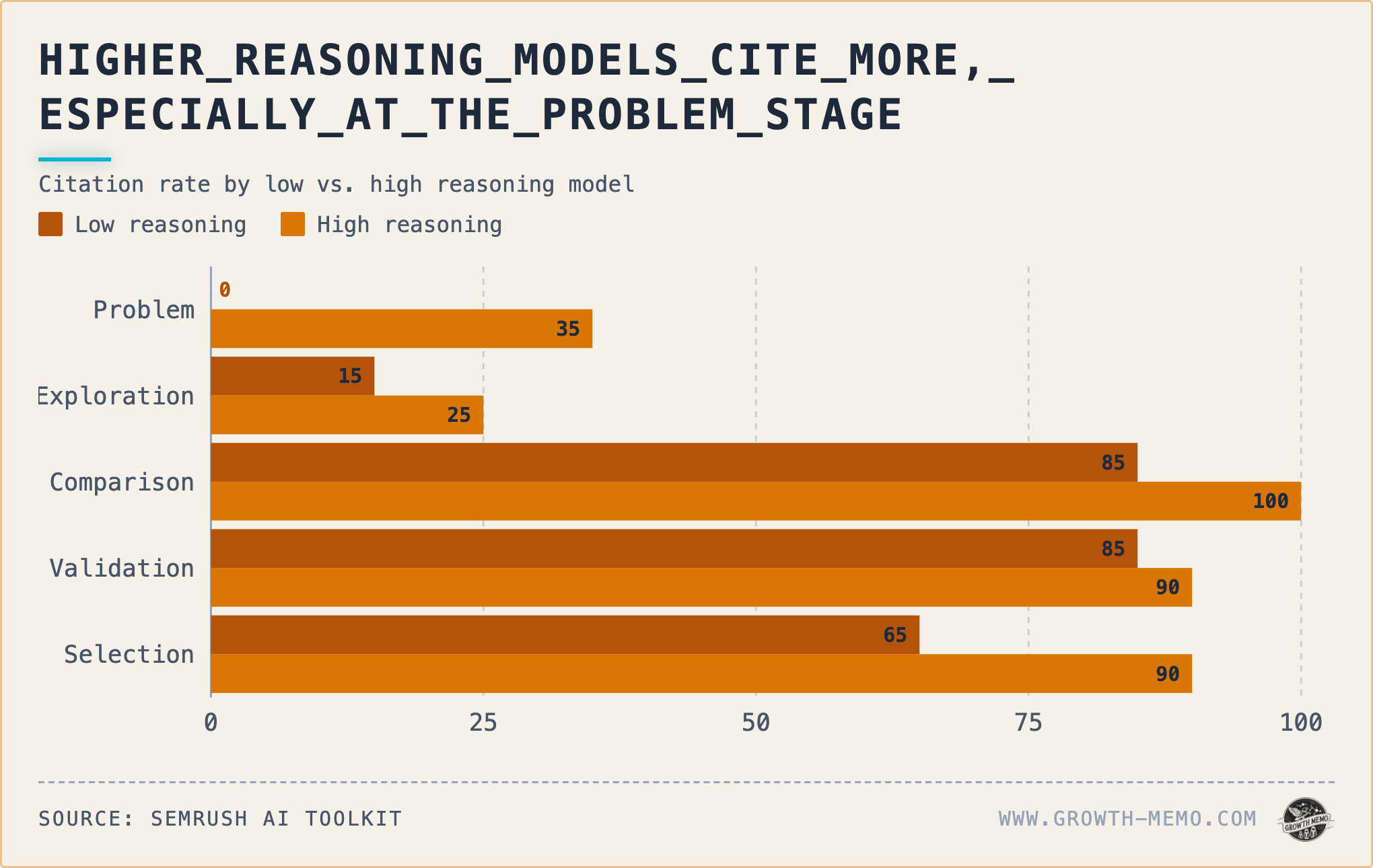
At the aggregate level, minimal reasoning fires 245 search queries across 100 prompts. High reasoning fires 1,130. When the model operates with high reasoning, it runs a mini investigation per prompt, and most of the investigation happens at the Comparison and Selection stages.
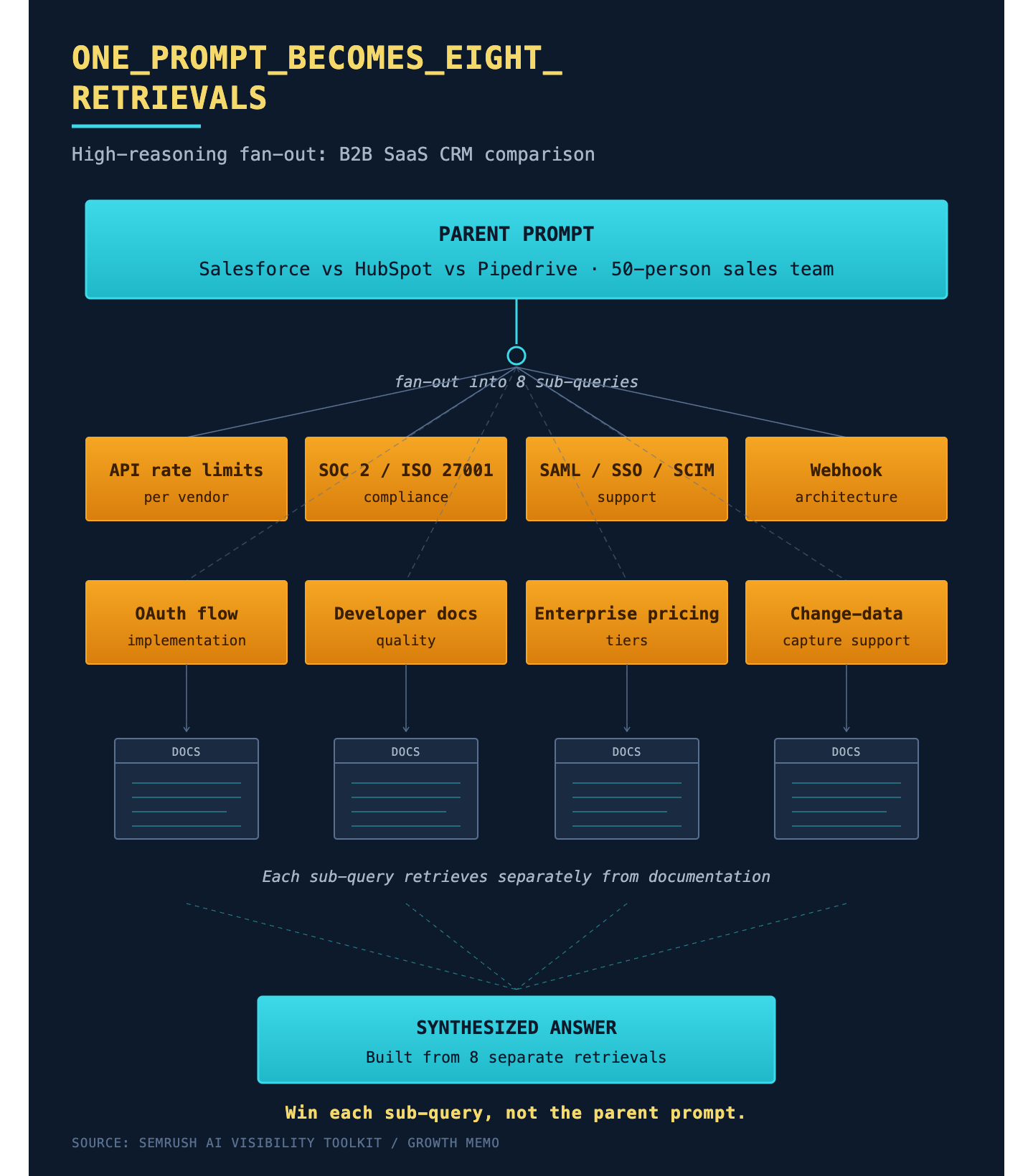
What does a fan-out actually look like? A B2B SaaS prompt under high reasoning comparing Salesforce, HubSpot, and Pipedrive for a 50-person sales team breaks into separate queries about API rate limits per vendor, SOC 2 / ISO 27001 compliance, SAML/SSO/SCIM support, webhook architecture, OAuth flow, developer documentation, enterprise pricing tiers, and change-data-capture support. Each becomes its own retrieval. The brand that wins the answer is the one whose documentation surfaces clean for each sub-query, not the one that ranks for the parent prompt.
The Selection stage has the widest per-response query variance: 0 to 40 fan-out queries on the same five-stage cohort. The driver is prompt specificity. Bounded prompts (like “should I finance through the dealer at 0% APR or use a bank?” or “draft an RFP to 3 SEO agencies”) run zero queries because the answer’s structure is given. Open-ended product builds (”shopping list for a $3,000 home gym” or “which travel card ecosystem fits our grocery spending?”) run 28 to 40 queries. The Selection stage isn’t bounded by one type of question, and the model’s research effort tracks how many degrees of freedom the prompt leaves on the table.
For marketers: Early-funnel visibility is a reasoning-mode story. If your buyers use ChatGPT with reasoning on, problem-stage and exploration-stage content is in play. If they don’t, you’re effectively invisible until Comparison.
Reasoning affects how brands appear in a conversation
An LLM session is a conversation, not a single query. The question that it opens up: Does a brand cited at the start of the journey carry through to the end? If yes, early-funnel visibility compounds. If not, every stage is a fresh fight.
When a brand gets cited in the Problem stage (step 1), does it survive to the Selection stage (step 5)? When using minimal reasoning: No. Zero journeys show this kind of persistence. In high reasoning: Yes. Brand continuity is maintained in 4 journeys across all 5 stages.
Within a single response, high reasoning also anchors harder on individual sources. 51 of 100 high-reasoning responses cite the same domain more than once in the same answer, vs. 26 of 100 for minimal. High reasoning quotes a source repeatedly when it commits to it.
Brand mentions tell a softer version of the same story. If you loosen the test from the cited domain to the brand name in the answer text, persistence shows up in 3 high-reasoning journeys (HubSpot across CRM Selection, American Express across Business Credit Cards, Sony and Canon across Mirrorless Camera) and 2 minimal-reasoning journeys (HubSpot, Mercury). Consumer Tech shows up here even though it doesn’t show up in the citation persistence table. Brands like Sony and Canon are mentioned through the conversation without the model linking out to them, which is its own form of category dominance and worth tracking separately.

High reasoning builds a consistent mental model of the solution space throughout a session. The headline finding: TOFU prompts have value. If a brand shows up at the Problem stage, it tends to carry through to Selection. Top-of-funnel content isn’t just brand awareness for AI visibility. It’s a leading indicator of where the model lands at decision time.
Two more implications:
All 4 persistent journeys are in Finance, which suggests persistence rides on the same authoritative-source content (regulatory pages, official brand sites) that drives the +28pp Finance lift overall.
For marketers running an account-based or category-creation play, reasoning-mode visibility is the prize. It’s the only mode where early-funnel content compounds into selection-stage citations.
Reasoning mode is a separate search engine
The brand that wins under minimal reasoning is not the brand that wins under high reasoning: 3 in 4 cited domains are different. The mix of source types is different. The stages where citations appear are different.
I’m excited about 2 findings in particular from this analysis:
1/ The first is measurement. We need to track low vs. high reasoning in our prompt trackers. It’s best to avoid an aggregate view because the mechanisms are truly different.
Bad news: This adds more effort and cost to prompt tracking. Good news: We can make prompt tracking a lot more accurate.
2/ The second is funnel stages. In the latest AI Mode user behavior study, I found that users react strongly to shortlists, demonstrating a similar behavior seen with Google’s classic search results where the top result matters most. That result made it seem to me that focusing on BOFU prompts that return shortlists is the game.
However, now we know there is value in TOFU prompts because of persistence: Brands that appear early in the buyer journey can persist all the way through. The best way to find that out for yourself is to map buyer journeys and track your persistence.
For Premium subscribers: winner & loser categories in high reasoning, buyer prompt journey worksheet and how Reddit performs
Most AI visibility strategies treat ChatGPT as a single system. The data says otherwise.
Reasoning mode and minimal mode pull from different corners of the web. Different source types. Different domains. Different winners. If your content strategy is built on the AEO / GEO / AI SEO you saw last year, it’s likely underperforming.
Below, premium subscribers get extra findings from this analysis, including which source types are losing ground, which ones are quietly taking over, and the categories where the gap is widest.
You’ll also get the Buyer Journey Prompt Map, a fillable worksheet for running an audit on your own brand across all 5 stages.
