

Growth Intelligence Brief #15
GPTBot hit a zero-authority site 470x harder than Googlebot. New data shows that doesn't translate to citations. This week: the 2 filters that actually determine AI visibility.

Welcome to another Growth Intelligence Brief, where organic growth leaders discover what matters - getting insights into the bigger picture and guidance on how to stay ahead of the competition.
Today’s Growth Intelligence Brief went out to 620 (+38) marketing leaders. As a free subscriber, you’re getting the first big story. Premium subscribers get the whole brief.
This week, we’re looking at what a $10 experiment with 60,000 AI-generated pages revealed about how GPTBot actually behaves, new citation data from 730,000 ChatGPT conversations, and what GPT-5.3 Instant’s web-blending update means for content that depends on being retrieved.
I’ll also connect the dots on what this all means for you.
GPTBot crawls everything - and cites almost nothing.
Here’s what happened:
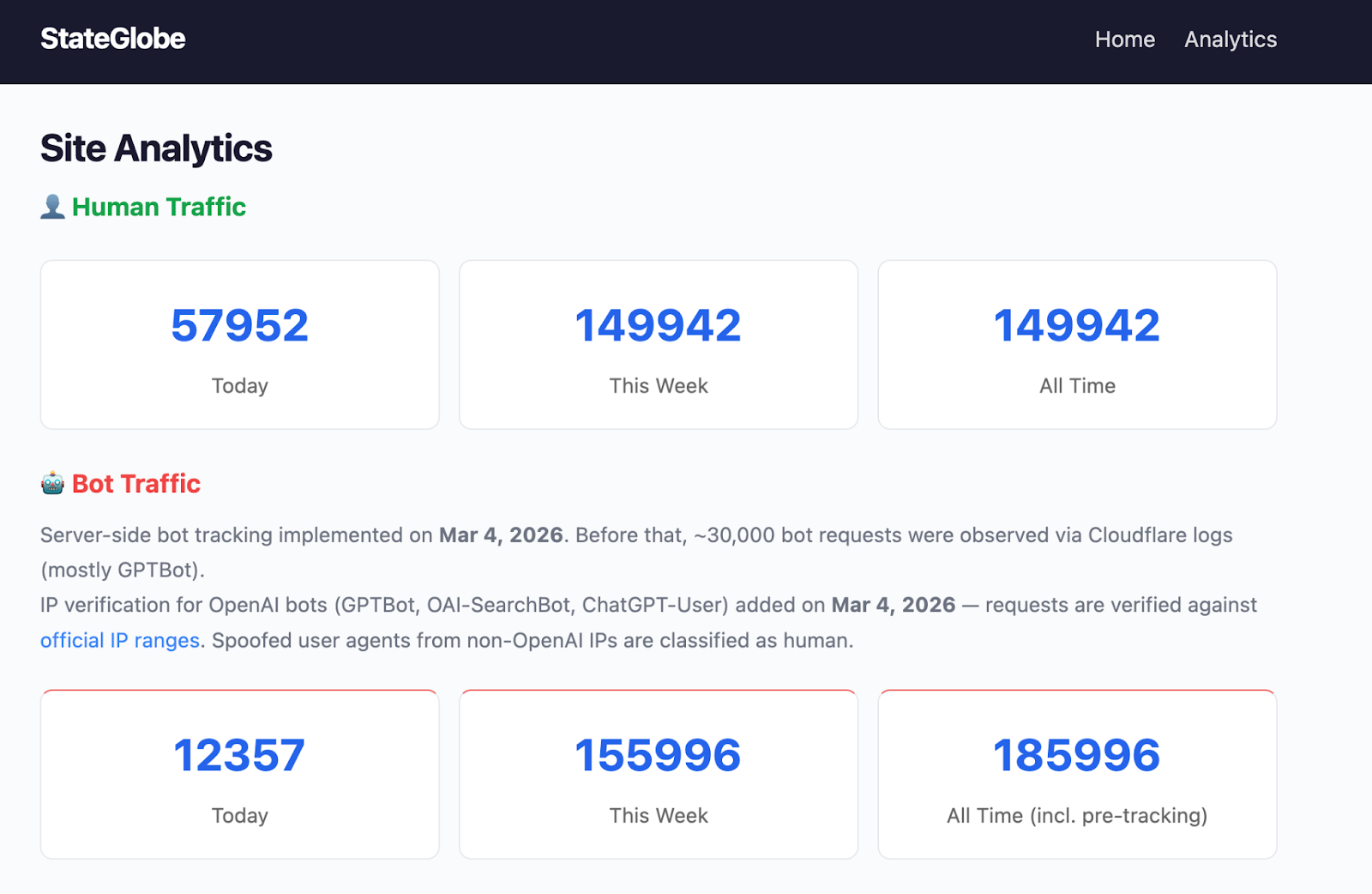
Metehan Yesilyurt built a 60K-page statistics website using GPT-4.1-nano for under $10, then tracked what happened next. He didn’t expect Googlebot… he expected nothing.
I did not expect GPTBot to crawl a brand-new, zero-backlink domain at the scale it did. That was the real discovery.
GPTBot showed up within minutes of deployment. In the first 12 hours, it made 29,000+ requests to a site with zero backlinks, zero social shares, and no Search Console submission. Googlebot made 11 requests in the same window. That’s a 470x difference in crawl intensity.
The site - stateglobe.com - was entirely AI-generated and deliberately thin. It was built as an experiment, not a real publishing effort. None of that stopped GPTBot from consuming it at roughly 1 request per second.
Yesilyurt also caught a detail most site owners miss: Without server-side tracking, you can’t see any of this. Bot traffic made up ~98% of all requests, but client-side analytics tools captured none of it. He verified individual bot identities against OpenAI’s published IP ranges, ruling out user-agent spoofing.
Why this news matters:
Metehan’s experiment proves the barrier to getting AI crawlers onto your site is effectively zero. GPTBot will find you whether you optimize for it or not - it found a brand new domain with no authority in minutes, and then for some reason stayed for hours.
His experiment results raise an important question: What’s the point of optimizing for AI crawlers? Does that access lead to anything?
A site crawled 30,000 times in 12 hours still gets deindexed by Google and almost certainly won’t appear in ChatGPT answers, because ingestion vs. citation operates on entirely different logic.
My take on this:
High crawl volume to your site from GPTBot is not evidence of AI visibility. It’s simply evidence that OpenAI is building its index, which will include a lot of content across the web that will never surface in a citation.
The experiment shows how hungry ChatGPT is for fresh and new content. While Google is very picky, probably to keep its index clean, ChatGPT can’t get enough. Important to note: ChatGPT crawled 78k times with the GPTBot user agent, but only 642 times with the ChatGPT-User user agent (as of March 8th). In other words, ChatGPT mostly crawls this site for model training. Not for showing it in answers.
Since the site is data-heavy (statistics), it’s prime steak for hungry AI crawlers. Now, the downside is that content used for training gets barely cited, so the question we have to ask ourselves is how much we want to be part of the training data as opposed to beachfront property for live web retrieval.
Here’s what to do:
Audit your logs, not your analytics: Stop relying on client-side tools like GA4 to measure AI crawler interest. You need server-side log analysis to differentiate between GPTBot (ingestion/training) and ChatGPT-User (live web retrieval).
Draw the line between training and retrieval: Decide if your proprietary data is something you want the model to train on. If you only want to be surfaced in live conversational answers, use your robots.txt to block GPTBot while keeping ChatGPT-User fully permitted.
Advance past crawl metrics: A massive crawl spike from an AI bot is not a KPI. Shift your content team’s focus from “are we being crawled?” to “are we providing answers worth citing?”
